引言
数据科学是一门激动人心的学科,让你能够将原始数据转化为理解、洞见和知识。《R for Data Science》的目标是帮助你学习 R 中最重要的工具,让你能够高效且可重复地进行数据科学工作,并在此过程中获得乐趣 😃。读完本书后,你将掌握利用 R 的最佳实践来应对各种数据科学挑战。
你将学到什么
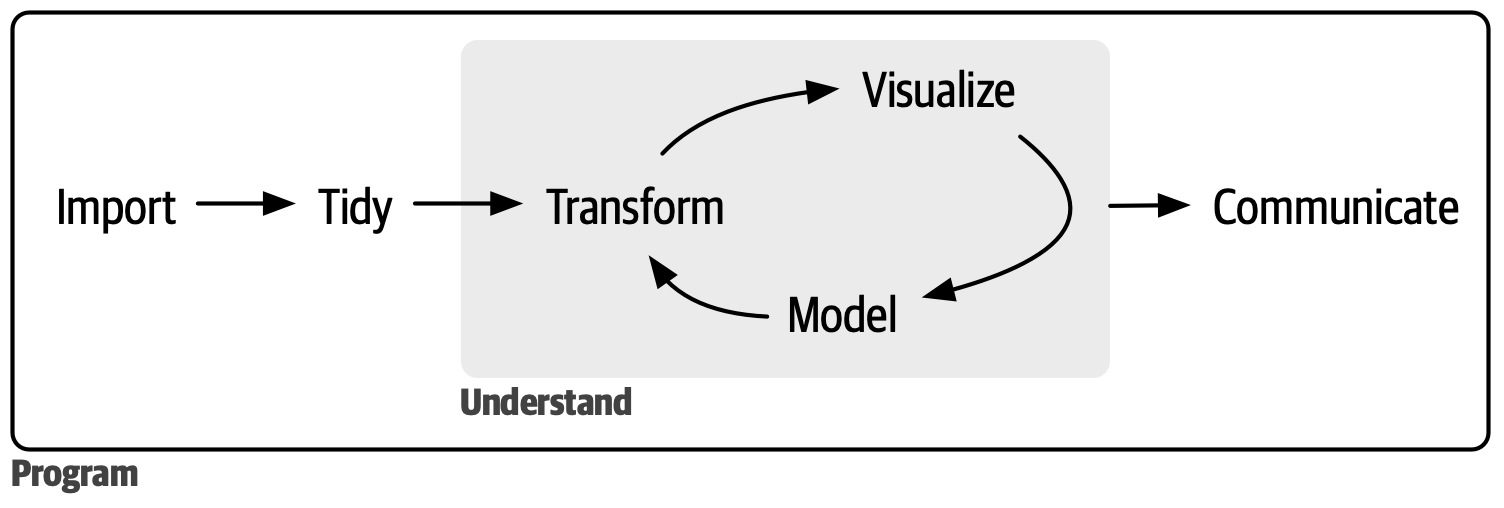
数据科学是一个广阔的领域,你不可能通过仅仅阅读一本书就掌握它的全部。本书旨在为你打下最重要工具那部分的坚实基础,并提供足够的相关知识,以便在必要时你能够找到资源去学习更多内容。我们认为典型数据科学项目的步骤大致如 Figure 1 所示。
首先,你必须将数据导入(import)到 R 中。这通常意味着将存储在文件、数据库或 Web 应用程序编程接口(API)中的数据加载到 R 的数据框中。如果你无法将数据导入 R,就无法对其进行数据科学工作!
一旦导入了数据,最好对其进行整理(tidy)处理。整理数据意味着以一种约定一致的形式存储它,使其语义与存储方式相匹配。简而言之,当你的数据整理后,每一列应该都是一个变量(variable),每一行应当都是一个观测(observation)。整洁形式的数据之所以重要,是因为约定一致的数据结构能让你集中精力回答数据本身相关的问题,而不是为了让数据符合不同的函数的要求而费力调整其格式和结构。
一旦拥有了整洁的数据,通常下一步就是对其进行变换(transform)。变换包括聚焦于感兴趣的观测(例如某个城市的所有人或去年的所有数据)、根据现有变量创建新变量(例如根据距离和时间计算速度)、以及计算一组摘要统计量(例如计数或均值)。整理和变换合称为处理(wrangling),因为将数据调整为适合工作形式的过程通常让人感觉像是一场战斗!
一旦拥有了包含所需变量的整洁数据,就有了两个生成知识的主要引擎:可视化和建模。它们各有优劣,互为补充,因此任何实际的数据分析都会在两者之间多次迭代。
可视化(Visualization)本质上是一项人类活动。一个好的可视化会向你展示意想不到的内容,或者引发数据本身相关的新问题。好的可视化还可能暗示对于这份数据你提出了错误的问题,或者你需要收集不同的数据。可视化可以给你带来惊喜,但它们难以大规模扩展,因为它们需要人类来逐一解读。
模型(Models)是可视化的互补工具。一旦你的问题足够精确,就可以使用模型来回答。模型本质上是数学或计算工具,因此它们通常易于扩展。即使不易扩展,购买更多的计算机通常也比付费购买更多的人脑智慧要便宜!但是每个模型都有各自的假设,而且就其本质而言,模型无法质疑其自身的假设。这意味着模型无法有颠覆性的惊喜,因为它的假设从根本上限制了它。
数据科学的最后一步是沟通(communication),这是任何数据分析项目中绝对关键的一部分。除非你能将结果传达给他人,否则无论你的模型和可视化让你对数据理解得多么透彻都没有价值,因为你无法让别人理解你的发现。
围绕所有这些工具的是编程(programming)。编程是一项贯穿始终的工具,你在数据科学项目的几乎每个环节都会用到它。你不需要成为编程专家也能成为一名成功的数据科学家,但学习更多的编程知识会带来回报,因为成为一名更好的程序员可以让你自动化常见任务,并且能够更轻松地解决新问题。
你将在每个数据科学项目中使用以上这些工具,但对于大多数项目来说,仅有这些还不够。这里大致有一个 80/20 法则:你可以使用本书中学到的工具解决每个项目中约 80% 的问题,但你仍然需要其他工具来解决剩下的 20%。在本书中,我们会为你指明可以学习更多内容的具体资源。
本书的组织结构
前面关于数据科学工具的描述大致是按照你在分析中使用它们的顺序组织的(当然,你会在它们之间多次迭代)。然而,根据我们的经验,首先学习数据导入和整理并不是最佳选择,因为 80% 的时候它是例行公事且枯燥的,而另外 20% 的时候它是古怪且令人沮丧的。这不是开始学习新内容的好起点!相反,我们将从对已经导入和整理后的数据进行可视化和变换开始。这样,当你读入并整理自己的数据时,你的动力会保持高涨,因为你知道这些痛苦是值得付出的。
在每一章中,我们都试图遵循一个一致的模式:从一些激发兴趣的例子开始,让你先看到全貌,然后再深入细节。本书的每一节都配有练习,帮助你练习所学内容。虽然跳过练习很诱人,但没有比在实际问题中进行练习更好的学习方法了。
本书不涉及的内容
有几个重要的话题本书没有涵盖。我们认为,必须严格专注于最核心的内容,以便你能尽快上手,这一点至关重要。这也意味着本书无法涵盖每一个重要的话题。
建模(Modeling)
建模对于数据科学极其重要,但这是一个宏大的话题,遗憾的是,我们没有足够的篇幅在这里对其进行应有的详尽讲解。要深入学习建模,我们强烈推荐阅读我们同事 Max Kuhn 和 Julia Silge 撰写的 Tidy Modeling with R。该书将教会你使用 tidymodels 系列包,正如你从名字中猜到的那样,它们与本书中使用的 tidyverse 系列包共享许多约定。
大数据
本书主要关注小型的、内存中的数据集。这是一个正确的起点,因为如果你没有处理小型数据的经验,就无法处理大规模数据。你在本书大部分内容中学到的工具可以轻松处理数百兆字节(megabytes, MB)的数据,只要稍加注意,通常也可以用它们来处理几千兆字节(gigabytes, GB)的数据。我们还将向你展示如何从数据库和 parquet 文件中获取数据,这两者通常用于存储大数据。你不一定需要能够处理整个数据集,但这不成问题,因为你通常只需要一个子集或亚人群样本集来回答你感兴趣的问题。
如果你经常处理更大规模的数据(比如 10–100 GB),我们建议深入学习 data.table。我们在这里不讲解它,因为它使用的接口与 tidyverse 不同,需要你学习一些不同的约定。然而,它的速度极快,如果你正在处理大数据,投入时间学习它是值得的,因为它带来的性能回报很高。
Python、Julia 及其它
在本书中,你不会学到关于 Python、Julia 或任何其他对数据科学有用的编程语言的内容。这并不是因为我们认为这些工具不好。它们很好!实际上,大多数数据科学团队使用混合语言,通常至少包括 R 和 Python。但我们坚信一次最好掌握一种工具,而 R 是一个极佳的起点。
预备知识
为了让你能从本书中获得最大收获,我们假设你已经具备了一些基础知识。你应该具备基本的数字素养,如果你已经有一些基本的编程经验会很有帮助。如果你以前从未编写过程序,你可能会发现 Garrett 编写的 Hands on Programming with R 是本书非常有价值的补充读物。
要运行本书中的代码,你需要四样东西:R、RStudio、一个称为 tidyverse 的 R 包集合,以及其他少量 R 包。包(Packages)是可重复 R 代码的基本单元。它们包含可复用的函数、描述如何使用这些函数的文档以及示例数据。
R
要下载 R,请访问 CRAN(comprehensive R archive network):https://cloud.r-project.org。R 每年发布一个新的主要版本,每年还有 2-3 个次要版本更新。定期更新 R 是个好习惯。升级可能会有点麻烦,特别是主要版本更新需要你重新安装所有的包,但拖延只会让未来更新变得更麻烦。对于本书,我们建议使用 R 4.2.0 或更高版本。
RStudio
RStudio 是用于 R 编程的集成开发环境(integrated development environment, IDE),你可以从 https://posit.co/download/rstudio-desktop/ 下载。RStudio 每年更新几次,当有新版本发布时它会自动通知你,因此无需手动检查。定期升级 RStudio 是个好主意,这样可以利用它最新、最好的功能。对于本书,请确保你至少安装了 RStudio 2022.02.0 版本。
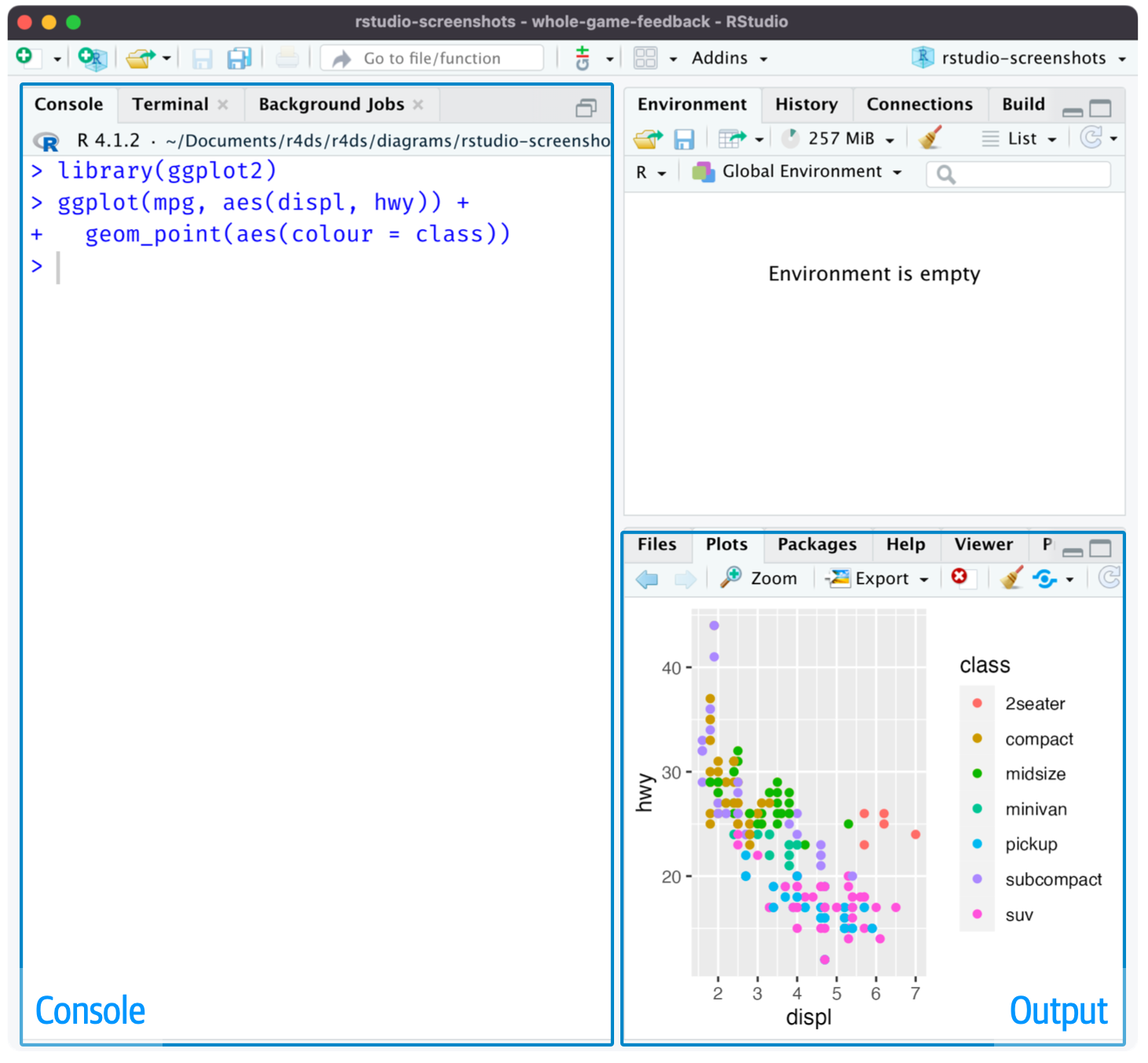
启动 RStudio 时(如 Figure 2 所示),你会看到界面中有两个关键区域:控制台(console)面板和输出(output)面板。目前,你只需要知道:在控制台面板中输入 R 代码,然后按回车键(Enter)运行它。随着学习的深入,你会了解更多内容!1
tidyverse 系列包
你还需要安装一些 R 包。R 包(package)是函数、数据和文档的集合,用于扩展基础 R 的功能。使用包是成功掌握 R 使用的关键。你在本书中将要学习的大多数包都是所谓的 tidyverse 的一部分。tidyverse 中的所有包都共享相同的数据哲学和 R 编程理念,并且旨在协同工作。
你可以用一行代码安装完整的 tidyverse:
install.packages("tidyverse")在你的电脑上,在控制台中输入上面这行代码,然后按回车键(Enter)运行它。R 会从 CRAN 下载这些包并将其安装到你的电脑上。
在使用 library() 加载包之前,你无法使用包中的函数、对象或帮助文件。一旦安装了包,你就可以使用 library() 函数加载它:
library(tidyverse)
#> ── Attaching core tidyverse packages ───────────────────── tidyverse 2.0.0 ──
#> ✔ dplyr 1.2.0 ✔ readr 2.1.6
#> ✔ forcats 1.0.1 ✔ stringr 1.6.0
#> ✔ ggplot2 4.0.2 ✔ tibble 3.3.1
#> ✔ lubridate 1.9.5 ✔ tidyr 1.3.2
#> ✔ purrr 1.2.1
#> ── Conflicts ─────────────────────────────────────── tidyverse_conflicts() ──
#> ✖ dplyr::filter() masks stats::filter()
#> ✖ dplyr::lag() masks stats::lag()
#> ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors这告诉你 tidyverse 加载了九个包:dplyr、forcats、ggplot2、lubridate、purrr、readr、stringr、tibble 和 tidyr。这些被认为是 tidyverse 的核心,因为你在几乎每次分析中都会用到它们。
tidyverse 中的包更新相当频繁。你可以通过运行 tidyverse_update() 来查看是否有可用更新。
其他包
还有许多其他优秀的包不属于 tidyverse,因为它们解决的是不同领域的问题,或者是基于一套不同的底层原则设计的。这并不意味着它们更好或更差;这只是意味着它们有所不同。换句话说,tidyverse 的补集并不是 messyverse(混乱宇宙),而是许多其他相互关联的包所构成的宇宙。随着你使用 R 处理更多的数据科学项目,你将学习到新的 R 包和思考数据的新方式。
在本书中,我们将使用许多 tidyverse 之外的包。例如,我们将使用以下包,因为它们提供了有趣的数据集,供我们在学习 R 的过程中使用:
install.packages(
c("arrow", "babynames", "curl", "duckdb", "gapminder",
"ggrepel", "ggridges", "ggthemes", "hexbin", "janitor", "Lahman",
"leaflet", "maps", "nycflights13", "openxlsx", "palmerpenguins",
"repurrrsive", "tidymodels", "writexl")
)我们还将使用其他一些包用于一次性的示例。你不需要现在就安装它们,只需记住,每当你看到像这样的错误时:
你需要运行 install.packages("ggrepel") 来安装该包。
运行 R 代码
上一节向你展示了运行 R 代码的几个示例。书中的代码看起来像这样:
1 + 2
#> [1] 3如果你在你的本地控制台中运行相同的代码,它将如下所示:
> 1 + 2
[1] 3这里有两个主要区别。在你的控制台中,你在 > 之后输入,这被称为提示符(prompt);而我们在书中不显示提示符。在书中,输出结果以 #> 开头作为注释显示;而在你的控制台中,它直接出现在你的代码之后。这两个区别意味着,如果你正在阅读本书的电子版,你可以轻松地将代码从书中复制并粘贴到控制台中。
在整本书中,我们使用一套一致的约定来管理代码样式:
其他 R 对象(如数据或函数参数)以代码字体显示,不带圆括号,例如
flights或x。有时,为了明确对象来自哪个包,我们会使用包名后跟两个冒号的形式,例如
dplyr::mutate()或nycflights13::flights。这也是有效的 R 代码。
致谢
本书英文原版致谢
本书不仅是 Hadley、Mine 和 Garrett 的成果,更是我们与 R 社区中许多人(无论是面对面还是在线)进行的许多对话的结果。我们非常感谢与大家的所有对话;非常感谢你们!
本书在开源环境中写成,许多人通过 GitHub pull request 做出了贡献。特别感谢通过 pull requests 贡献改进的全部 290 位朋友(按 GitHub 用户名的字母顺序排列):@0solarfox0, @a-rosenberg, Tim Becker (@a2800276), Abinash Satapathy (@Abinashbunty), Adam Gruer (@adam-gruer), Adi Pradhan (@adidoit), A. s. (@Adrianzo), Aep Hidyatuloh (@aephidayatuloh), Andrea Gilardi (@agila5), Ajay Deonarine (@ajay-d), Alan Feder (@AlanFeder), Alberto Agudo (@alberto-agudo), Albert Rapp (@AlbertRapp), @aleloi, pete (@alonzi), Alex (@ALShum), Andrew M. (@amacfarland), Andrew Landgraf (@andland), @andyhuynh92, Angela Li (@angela-li), LOU Xun (@aquarhead), @ariespirgel, @august-18, Michael Henry (@aviast), Azza Ahmed (@azzaea), Steven Moran (@bambooforest), Brian G. Barkley (@BarkleyBG), Mara Averick (@batpigandme), Oluwafemi OYEDELE (@BB1464), Brent Brewington (@bbrewington), Beatriz Milz (@beatrizmilz), Bill Behrman (@behrman), ben-herbertson (@benherbertson), Ben Marwick (@benmarwick), Ben Steinberg (@bensteinberg), Benjamin Yeh (@bentyeh), Betul Turkoglu (@betulturkoglu), Brandon Greenwell (@bgreenwell), Bianca Peterson (@BinxiePeterson), Birger Niklas (@BirgerNi), Tom Corcoran (@boardtc), Christian (@c-hoh), Caddy (@caddycarine), Camille V Leonard (@camillevleonard), @canovasjm, Alex Reinhart (@capnrefsmmat), Cedric Batailler (@cedricbatailler), Christina Wei (@christina-wei), Christian Mongeau (@chrmongeau), Cooper Morris (@coopermor), Colin Gillespie (@csgillespie), Rademeyer Vermaak (@csrvermaak), Chloe Thierstein (@cthierst), Chris Saunders (@ctsa), Abhinav Singh (@curious-abhinav), Curtis Alexander (@curtisalexander), Christian G. Warden (@cwarden), Charlotte Wickham (@cwickham), Daniel Stafford (@daniel-stafford), Kenny Darrell (@darrkj), David Kane (@davidkane9), David (@davidrsch), David Rubinger (@davidrubinger), David Clark (@DDClark), Derwin McGeary (@derwinmcgeary), Daniel Gromer (@dgromer), Qasim Alhammad (@Divider85), @djbirke, Danielle Navarro (@djnavarro), David Laehnemann (@dlaehnemann), Russell Shean (@DOH-RPS1303), Devin Pastoor (@dpastoor), @DSGeoff, Devarshi Thakkar (@dthakkar09), Julian During (@duju211), Dylan Cashman (@dylancashman), @e-linc, Dirk Eddelbuettel (@eddelbuettel), Edwin Thoen (@EdwinTh), Ahmed El-Gabbas (@elgabbas), Ercan Karadas (@ercan7), Eric Kitaif (@EricKit), Eric Watt (@ericwatt), Erik Erhardt (@erikerhardt), Etienne B. Racine (@etiennebr), Everett Robinson (@evjrob), @fellennert, Filip Edström (@fileds), Flemming Miguel (@flemmingmiguel), Floris Vanderhaeghe (@florisvdh), @funkybluehen, @gabrivera, Garrick Aden-Buie (@gadenbuie), Peter Ganong (@ganong123), Gerome Meyer (@GeroVanMi), Gleb Ebert (@gl-eb), Josh Goldberg (@GoldbergData), Max Ranieri (@granieri), bahadir cankardes (@gridgrad), Metehan GÜNGÖR (@gungorMetehan), Gustav W Delius (@gustavdelius), Hao Chen (@hao-trivago), Harris McGehee (@harrismcgehee), @hbeale, Hendrik Weisser (@hendrikweisser), Hengni Cai (@hengnicai), Iain Stenson (@Iain-S), Ian Sealy (@iansealy), Ian Lyttle (@ijlyttle), Ivan Krukov (@ivan-krukov), Jacob Kaplan (@jacobkap), Jazz Weisman (@jazzlw), John Blischak (@jdblischak), John D. Storey (@jdstorey), Gregory Jefferis (@jefferis), Jeffrey Stevens (@JeffreyRStevens), 蒋雨蒙 (@JeldorPKU), Jennifer (Jenny) Bryan (@jennybc), Jen Ren (@jenren), Jeroen Janssens (@jeroenjanssens), @jeromecholewa, Jim Hester (@jimhester), JJ Chen (@jjchern), Jacek Kolacz (@jkolacz), Joanne Jang (@joannejang), @johannes4998, John Sears (@johnsears), @jonathanflint, @JonathanNankivell, Jon Calder (@jonmcalder), Jon Page (@jonpage), Jon Harmon (@jonthegeek), JooYoung Seo (@jooyoungseo), Justinas Petuchovas (@jpetuchovas), Jordan Bradford (@jrdnbradford), Jeffrey Arnold (@jrnold), Jose Roberto Ayala Solares (@jroberayalas), Joyce Robbins (@jtr13), @juandering, Julia Stewart Lowndes (@jules32), @JustinianOfByzantium, Sonja (@kaetschap), Kara Woo (@karawoo), Katrin Leinweber (@katrinleinweber), Karandeep Singh (@kdpsingh), Kevin Perese (@kevinxperese), @kew24, Kevin Ferris (@kferris10), Kirill Sevastyanenko (@kirillseva), Jonathan Kitt (@KittJonathan), Tom Klein (@kleintom), @koalabearski, Kirill Müller (@krlmlr), Kai Tang (唐恺) (@ktang), Rafał Kucharski (@kucharsky), Kevin Wright (@kwstat), Noah Landesberg (@landesbergn), Lawrence Wu (@lawwu), Layal Christine Lettry (@Layalchristine24), Leonardo R. Jorge (@leorjorge), Luong Vuong (Leo) (@leovuong), Zoë Turner (@Lextuga007), @lindbrook, Lionel Henry (@lionel-), Wouter Overmeire (@lodagro), Luke W. Johnston (@lwjohnst86), Kara de la Marck (@MarckK), Kunal Marwaha (@marwahaha), Matan Hakim (@matanhakim), Dr. Ryan McShane (@math-mcshane), Matthias Liew (@MatthiasLiew), Matthew Vine (@MattTheCuber), Matt Wittbrodt (@MattWittbrodt), Mauro Lepore (@maurolepore), Mark Beveridge (@mbeveridge), McEwen Khundi (@mcewenkhundi), Stefan Schreiber (@mcsnowface), Matthew Davis (@mdavis-xyz), Matt Herman (@mfherman), Mackenzie Haight (@mghaight), Michael Boerman (@michaelboerman), Michael Grund (@michaelgrund), Mitsuo Shiota (@mitsuoxv), Matthew Hendrickson (@mjhendrickson), @MJMarshall, Misty Knight-Finley (@mkfin7), Mohammed Hamdy (@mmhamdy), Maxim Nazarov (@mnazarov), María Paula Caldas (@mpaulacaldas), Mustafa Ascha (@mustafaascha), Nelson Areal (@nareal), Nate Olson (@nate-d-olson), Nathanael (@nateaff), @nattalides, Andrea Scalia (@ndrscalia), Ned Western (@NedJWestern), Nick Clark (@nickclark1000), @nickelas, Nirmal Patel (@nirmalpatel), Nischal Shrestha (@nischalshrestha), Nicholas Tierney (@njtierney), Jakub (@Nowosad), Nick Pullen (@nstjhp), @olivier6088, Olivier Cailloux (@oliviercailloux), @olivroy, Robin Penfold (@p0bs), Pablo E. Garcia (@pabloedug), Paul Adamson (@padamson), Pasha (@PashaMS), Penelope Yong (@penelopeysm), Peter Wildeford (@peterhurford), Peter Baumgartner (@petzi53), Patrick C. Kennedy (@pkq), Pooya Taherkhani (@pooyataher), Youzhi Yu (@PursuitOfDataScience), Radu Grosu (@radugrosu), Raffaele Mancuso (@raffaem), Ranae Dietzel (@Ranae), Ralph Straumann (@rastrau), Rayna M Harris (@raynamharris), Reece Goding (@ReeceGoding), Robin Gertenbach (@rgertenbach), Jajo (@RIngyao), Riva Quiroga (@rivaquiroga), Richard Knight (@RJHKnight), Richard Zijdeman (@rlzijdeman), @robertchu03, Robin Kohrs (@RobinKohrs), Robin Lovelace (@Robinlovelace), Emily Robinson (@robinsones), Rob Tenorio (@robtenorio), Rod Mazloomi (@RodAli), Rohan Alexander (@RohanAlexander), Romero Morais (@RomeroBarata), Albert Y. Kim (@rudeboybert), Saghir (@saghirb), Hojjat Salmasian (@salmasian), Jonas Otten (@sauercrowd), Vebash Naidoo (@sciencificity), Seamus McKinsey (@seamus-mckinsey), @seanpwilliams, Luke Smith (@seasmith), Matthew Sedaghatfar (@sedaghatfar), Sebastian Kraus (@sekR4), Sam Firke (@sfirke), Shannon Ellis (@ShanEllis), @shleeneu, @shoili, Christian Heinrich (@Shurakai), S’busiso Mkhondwane (@sibusiso16), SM Raiyyan (@sm-raiyyan), Jakob Krigovsky (@sonicdoe), Stephan Koenig (@stephan-koenig), Stephen Balogun (@stephenbalogun), Steven M. Mortimer (@StevenMMortimer), Steven Primeaux (@stevenprimeaux), Stéphane Guillou (@stragu), Sulgi Kim (@sulgik), Sergiusz Bleja (@svenski), Tal Galili (@talgalili), Kevin Tappe (@tappek), Alec Fisher (@Taurenamo), Todd Gerarden (@tgerarden), Nic Crane (@thisisnic), Tom Godfrey (@thomasggodfrey), Tim Broderick (@timbroderick), Tim Waterhouse (@timwaterhouse), TJ Mahr (@tjmahr), Thomas Klebel (@tklebel), Tom Prior (@tomjamesprior), Terence (@tteo), @twgardner2, Ulrik Lyngs (@ulyngs), Shinya Uryu (@uribo), Martin Van der Linden (@vanderlindenma), Walter Somerville (@waltersom), @werkstattcodes, Will Beasley (@wibeasley), Yihui Xie (@yihui), Yiming Paul Li (@yimingli), @yingxingwu, Enki Wang (@ynsec37), Hiroaki Yutani (@yutannihilation), Yu Yu Aung (@yuyu-aung), Yvonne Fröhlich (@yvonnefroehlich), Yongyi Zeng (@yyzeng), Zach Bogart (@zachbogart), @zeal626, Zeki Akyol (@zekiakyol).
本书中文译版致谢
本书中文译版由陆震组织「OpenBioStat R for Data Science (2e) 中文版」翻译小组(成员:陆震、夏鑫辛)翻译并维护。非常感谢本书中文译版所有参与翻译和校对的志愿者们的无私奉献和辛勤付出!
本书中文译版在开源环境中写成,许多人通过 GitHub pull request 做出了贡献。特别感谢通过 pull requests 贡献改进的全部 2 位朋友(按 GitHub 用户名的字母顺序排列):@Copilot, Zhen Lu (@Leslie-Lu).
最后,我们感谢 “R for Data Science (2e)” 原作者 Hadley Wickham、Mine Çetinkaya-Rundel 和 Garrett Grolemund 的无私奉献和卓越贡献。
版本说明
本书英文原版版本说明
本书英文原版的在线版本可在 https://r4ds.hadley.nz 访问。在实体书各次重印之间,其在线版本将持续更新。本书英文原版的源代码可在 https://github.com/hadley/r4ds 获得。本书英文原版由 Quarto 驱动,它使得编写结合文本和可执行代码的书籍变得非常容易。
本书中文译版版本说明
本书中文译版的在线版本可在 https://openbiostat.github.io/R-for-Data-Science-2e-Chinese/ 访问,在线版本将持续更新。目前本书中文译版还没有纸质出版,如果读者是出版人员,并有意愿负责出版本书,请通过 luzh29@mail2.sysu.edu.cn 联系我们。本书中文译版的源代码可在 https://github.com/openbiostat/R-for-Data-Science-2e-Chinese 获得。本书中文译版同样由 Quarto 驱动。
tidyverse 系列包版本信息
| Package | Version | Source |
|---|---|---|
| broom | 1.0.12 | RSPM |
| cli | 3.6.5 | RSPM |
| conflicted | 1.2.0 | RSPM |
| dbplyr | 2.5.1 | RSPM |
| dplyr | 1.2.0 | RSPM |
| dtplyr | 1.3.3 | RSPM |
| forcats | 1.0.1 | RSPM |
| ggplot2 | 4.0.2 | RSPM |
| googledrive | 2.1.2 | RSPM |
| googlesheets4 | 1.1.2 | RSPM |
| haven | 2.5.5 | RSPM |
| hms | 1.1.4 | RSPM |
| httr | 1.4.7 | RSPM |
| jsonlite | 2.0.0 | RSPM |
| lubridate | 1.9.5 | RSPM |
| magrittr | 2.0.4 | RSPM |
| modelr | 0.1.11 | RSPM |
| pillar | 1.11.1 | RSPM |
| purrr | 1.2.1 | RSPM |
| ragg | 1.5.0 | RSPM |
| readr | 2.1.6 | RSPM |
| readxl | 1.4.5 | RSPM |
| reprex | 2.1.1 | RSPM |
| rlang | 1.1.7 | RSPM |
| rstudioapi | 0.18.0 | RSPM |
| rvest | 1.0.5 | RSPM |
| stringr | 1.6.0 | RSPM |
| tibble | 3.3.1 | RSPM |
| tidyr | 1.3.2 | RSPM |
| tidyverse | 2.0.0 | RSPM |
| xml2 | 1.5.2 | RSPM |
如果你想全面了解 RStudio 的所有功能,请参阅 RStudio 用户指南:https://docs.posit.co/ide/user。↩︎